| The MPI implementation of a
hydrocode usually consists in splitting the mesh in a number of
submeshes equal to the number of processing elements (processors). Each
processor can only access its own submesh, and has to communicate with
its "neighbours" so as to set the hydrodynamic variables in its ghost
zones. The MPI implementation of FARGO obeys this general picture, but
it is subject to an important restriction: normally, it is a good idea
to split the mesh in Nx*Ny submeshes (with Nx*Ny=number of CPUs), in
such a way that Nx and Ny are proportionnal to the number of zones
respectively in x and y.
This ensures that the amount of communications between processors will
be as small as possible. For instance, the figure below shows how the
mesh was split on a 12-processor run of the code JUPITER for one of the
test problems of the EU
hydrocode comparison: |
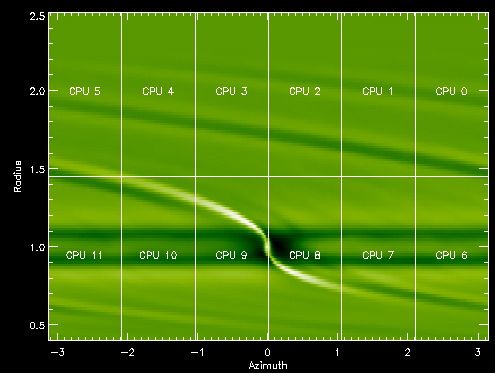 |
We see that the mesh is split both
in azimuth and radius. Such a splitting is not possible with FARGO.
Indeed, the FARGO algorithm implies azimuthal displacement of material
of several zones over one timestep. If the mesh were split in azimuth,
the communication between two processors could be very expensive (and
tricky to implement), as one of them (the upstream one) should send
many zone layers to the downstream one. For this reason, in the MPI
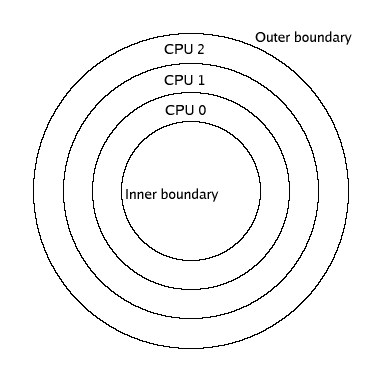
implementation of FARGO, the mesh is exclusively split radially, in a
number of rings equal to the number of processors, as depicted
below.
|
 |
The implementation of such a
splitting is obviously very simple, but not as efficient as a radial
and azimuthal splitting. The amount of communication is not optimal.
Furthermore, since only one communication is performed per
hydrodynamical
timestep, the number of zone layers that one processor needs to send to
its neighbors is equal to 5 (4 for a standard ZEUS-like scheme, plus
one for the viscous stress), which is a relatively large number (larger
for instance than in the Godunov method code JUPITER, where the
communication layers are only 2 zone wide).
One should therefore remember that the MPI implementation of FARGO, owing to the very nature of the FARGO algorithm and the adopted numerical scheme, is not very performant, and that one will only get a good scaling for a large number of zones radially. This should not be a problem anyway since FARGO is very fast even on a sequential platform, so one will need to run it on a parallel platform only at very large resolution, in which case the speed scaling provided by MPI will be satisfactory. |
We conclude this section with two
remarks about runtime details:
|